This project was completed by Jessalyn Chuang, Neha Manish Shah, Michelle Schultze, and Zixiao Tan (Prairie Dog Team) for the Spring 2025 section of IDS 705: Principles of Machine Learning at Duke University.
Overview
Electricity prices in wholesale energy markets are notoriously volatile, driven by demand spikes, renewable intermittency, and fuel cost fluctuations. Accurate short-term price forecasting enables grid operators, traders, and policymakers to make better decisions. This project benchmarks tree-based and deep learning models for forecasting ERCOT (Electric Reliability Council of Texas) hub prices across multiple time horizons using only publicly available data.
Target Variable
ERCOT Average Hub Real-Time Locational Marginal Price (LMP) — the wholesale electricity price ($/MWh) at the system hub, sampled hourly.
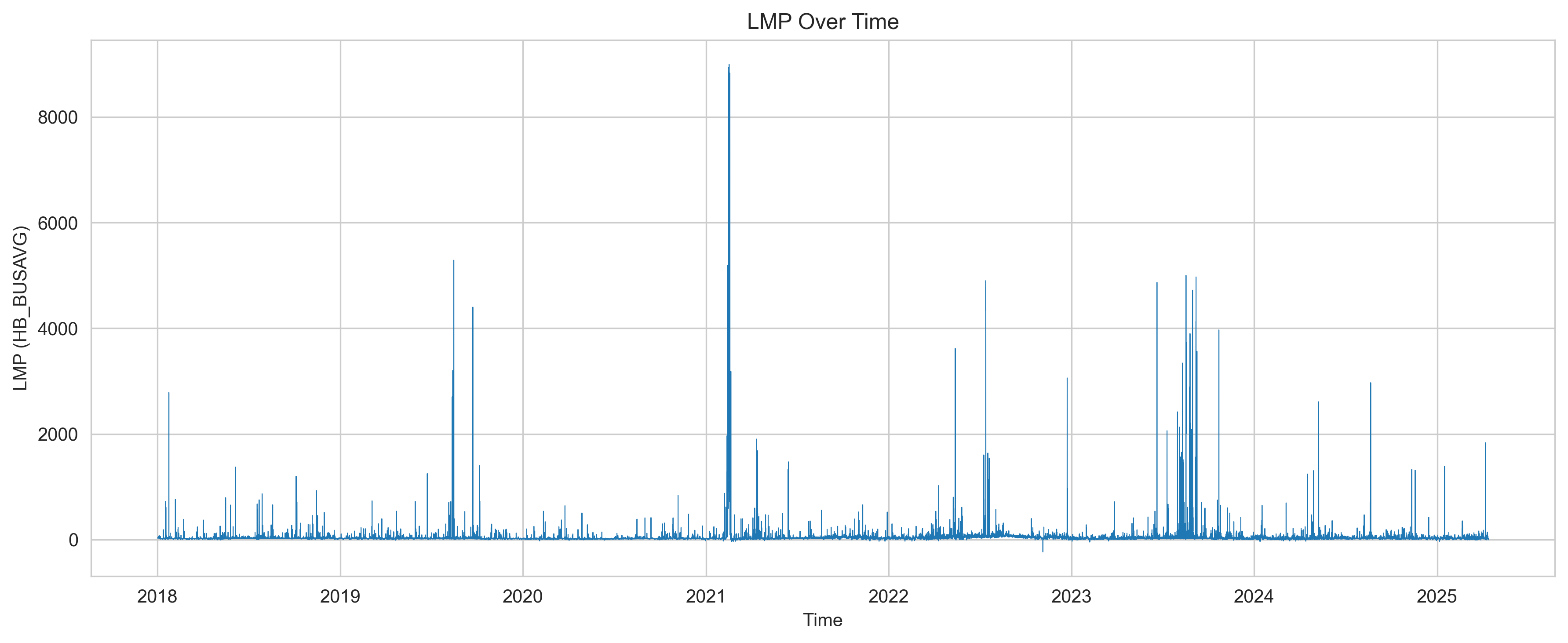
Data Sources
| Source | Features |
|---|---|
| GridStatus.io | Real-time ERCOT load, generation fuel mix (wind, solar, gas, coal), solar generation |
| EIA (Energy Information Administration) | Regional electricity demand and supply statistics |
| Plano, TX Weather Station | Hourly dry-bulb and wet-bulb temperatures |
| Henry Hub Natural Gas | Daily spot prices |
- Time period: 2018 – 2025
- Granularity: Hourly (aligned via forward-fill for daily series)
- Processed dataset: ~60,000 hourly observations after cleaning
Feature Engineering
- Lagged LMP values (1h, 24h, 168h)
- Hour-of-day, day-of-week, month cyclical encodings
- Rolling means and standard deviations of load and generation
- Wet-bulb temperature (heat stress proxy)
- Natural gas price as fuel cost signal
Models
| Model | Type | Best For |
|---|---|---|
| LightGBM | Gradient Boosted Trees | 1-hour ahead forecasting |
| XGBoost | Gradient Boosted Trees | Baseline comparison |
| LSTM | Recurrent Neural Network | 1-day ahead forecasting |
| GRU | Recurrent Neural Network | 1-day ahead forecasting |
Hyperparameters tuned using Optuna (Bayesian optimization). All models evaluated on rolling-origin cross-validation — a time-aware resampling strategy that prevents data leakage.
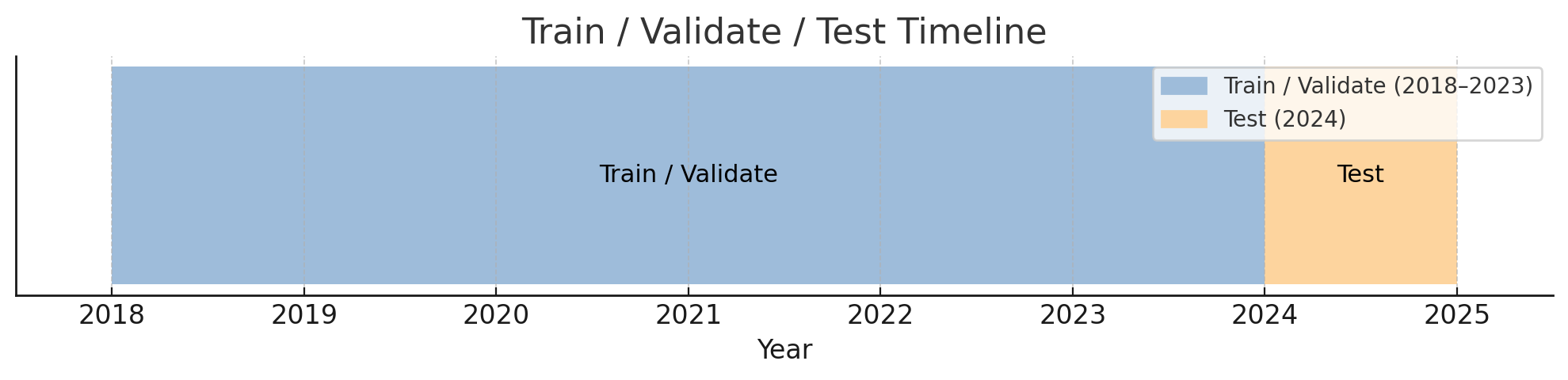
Results Summary
| Horizon | Best Model | Key Metric |
|---|---|---|
| 1-hour ahead | LightGBM | Lowest MAE & RMSE |
| 1-day ahead | LSTM / GRU | Outperform tree methods |
| 1-week ahead | Mixed | High uncertainty across all models |
Observation: Tree-based models capture short-term autocorrelation efficiently; recurrent networks better model the multi-step temporal dependencies at the 1-day horizon.
Feature Importance (SHAP Analysis)
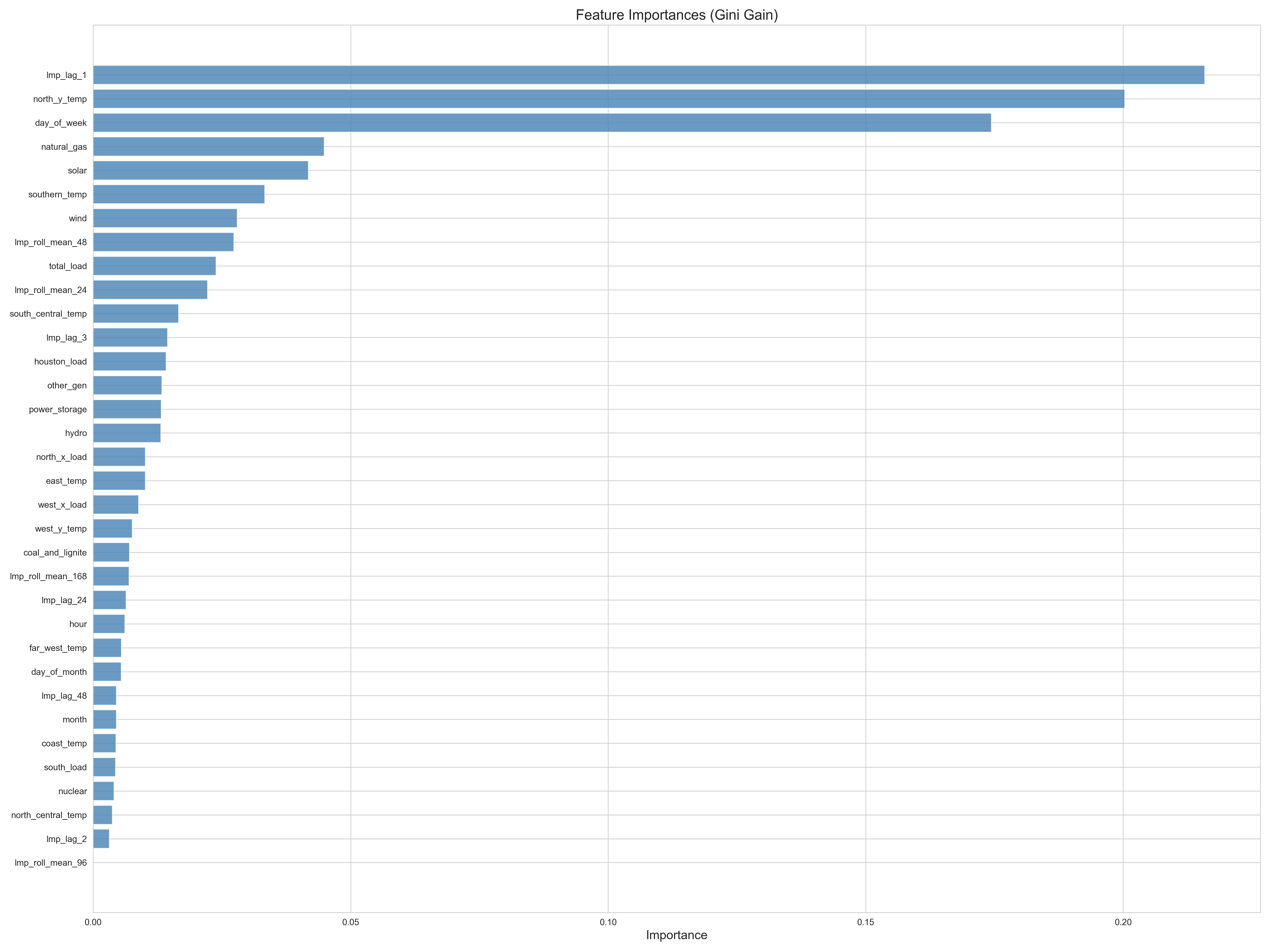
The most predictive features across all models:
- Lagged LMP prices (1h and 24h lags) — strongest signal
- Regional temperatures — demand-side proxy
- Natural gas price — supply-side cost driver
- Time-of-day features — captures intraday demand patterns
Technical Stack
- Language: Python
- ML/DL:
lightgbm,xgboost,torch(LSTM/GRU) - Optimization:
optuna - Analysis:
pandas,numpy,scikit-learn,statsmodels - Reproducibility: GitHub Actions CI for automated notebook rendering