

FinCom (Financial Committee) is a supervisor-based multi-agent framework built with LangGraph for committee-style financial decision-making. Three domain-specialized agents—Research, Quantitative, and Risk—each powered by Gemini-2.5-Flash with ReAct reasoning loops and constrained toolsets, collaborate under a central Supervisor to produce unified financial recommendations. Evaluation is conducted via LangSmith’s LLM-as-a-Judge pipeline for scalable, reproducible assessment.
Part I: Problem Statement
LLM-powered multi-agent systems are reshaping financial analysis, with specialized agents mirroring institutional trading desks for research, quantitative modeling, and risk management. However, existing frameworks suffer from sycophancy—agents echo peer reasoning rather than reasoning independently—leading to consensus collapse. This mirrors behavioral-finance biases like herding and overreaction, undermining reliability in autonomous systems. Current approaches either lack explicit governance or rely on rigid adversarial workflows that are difficult to integrate. FinCom addresses this with a modular, prompt-only architecture requiring no task-specific fine-tuning.
| Agent | Tools | Functionality |
|---|---|---|
| Research Agent | Web Search, SEC Filing Analyzer, Market Data Retrieval | Real-time information retrieval with source attribution; extraction and summarization of 10-K, 10-Q, 8-K filings (MD&A, Risk Factors, Financial Statements); price aggregates, snapshots, SMA, EMA, RSI, MACD |
| Quant Agent | Technical Indicator Computation, Strategy Backtesting, Correlation Analysis | RSI, SMA, Bollinger Bands calculation; SMA_CROSS and RSI_MEANREV over historical data; inter-asset correlation for diversification and hedging |
| Risk Management Agent | Volatility & Drawdown Calculator, Value-at-Risk (VaR), Stress Testing, Qualitative Risk Narratives | Annualized volatility and maximum drawdown from log returns; 99% confidence VaR via historical simulation; adverse scenario analyses; regulatory, geopolitical, and competitive risk factors |
Part II: Multi-Agent Solution
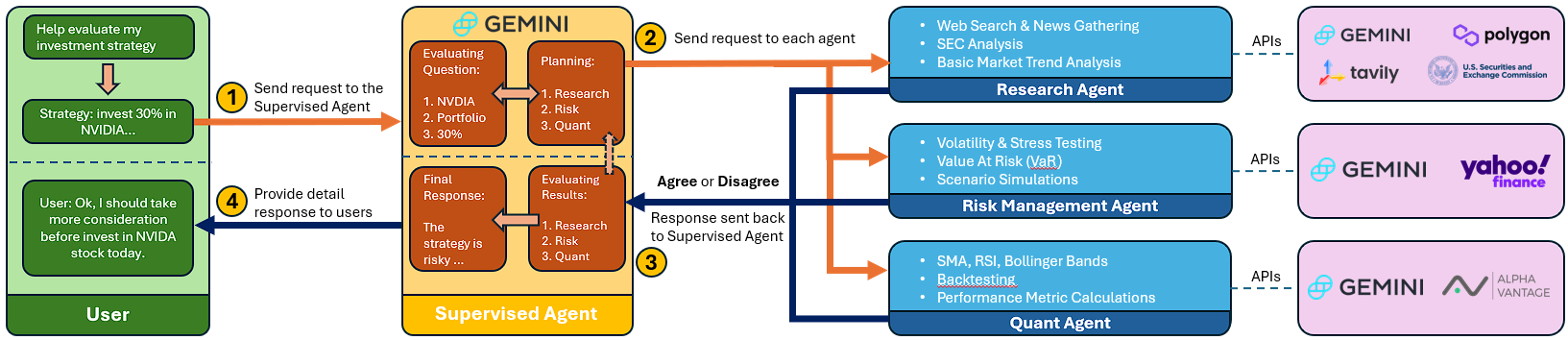
The system is built as a LangGraph state machine, where each agent is instantiated as a LangGraph node connected to Gemini-2.5-Flash with role-specific system prompts and constrained tool access. The Supervisor node handles intent parsing, task decomposition, inter-agent coordination, iterative validation, and final synthesis. All agents operate in a ReAct loop (Reason + Act) for structured, step-by-step tool use.
- Research Agent — Runs a ReAct loop over tools for web search (with source attribution), SEC filing analysis (10-K, 10-Q, 8-K extraction of MD&A, Risk Factors, and Financial Statements with LLM-powered summarization), and real-time market data retrieval (price aggregates, snapshots, SMA, EMA, RSI, MACD).
- Quant Agent — Executes technical indicator computation (RSI, SMA, Bollinger Bands), strategy backtesting (SMA_CROSS and RSI_MEANREV over historical data), and correlation analysis (inter-asset correlation for diversification and hedging).
- Risk Management Agent — Computes annualized volatility and maximum drawdown from log returns, Value-at-Risk (VaR) at 99% confidence via historical simulation, stress testing under adverse scenario analyses, and integrates qualitative risk narratives (regulatory, geopolitical, and competitive factors).
The Supervisor orchestrates a structured deliberation cycle: each agent independently reviews peers’ outputs, flagging inconsistencies or unsupported claims. The Supervisor mediates exchanges until consensus or justified dissent is reached, ensuring the final recommendation reflects both critique and convergence.
Part III: Evaluation
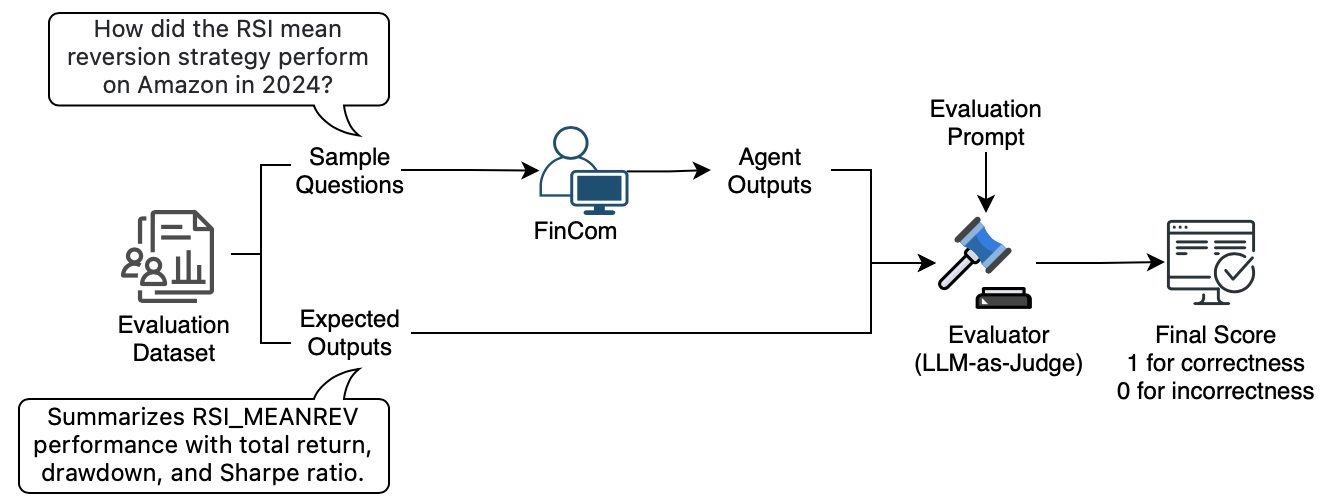
Evaluation is conducted through LangSmith, using a structured LLM-as-a-Judge pipeline for consistent, scalable assessment of reasoning quality. Each agent’s response is compared against hand-labeled reference answers: a score of 1 is assigned if the output includes all key elements without contradictions, and 0 otherwise. Each evaluation is repeated to mitigate stochastic variability, and averaged results are reported.
Dataset: 120 handcrafted data points across four task categories—research-heavy, quant-heavy, risk-management-oriented, and joint investment plan evaluations—with 30 instances each. All tasks are manually designed, annotated, and verified to reflect realistic end-to-end financial workflows.
Results:
| Method | Research | Quant Finance | Risk Management | Investment Plan | Overall Avg |
|---|---|---|---|---|---|
| Disagree or Commit (DoC) | 63.3% | 89.7% | 66.6% | 66.8% | 71.6% |
| Baseline (no DoC) | 56.6% | 83.3% | 50.0% | 56.3% | 61.6% |
Table: Performance comparison of average hit-rate across task categories for agents with and without the Disagree & Commit (DoC) prompting strategy. Scores represent the proportion of correct or complete reasoning steps according to LLM-as-a-Judge evaluation.
Across all domains, the DoC protocol improved decision quality and reasoning robustness compared to the consensus-based baseline. Agents operating under DoC achieved an average accuracy of 71.6%, outperforming the baseline’s 61.6%. The largest gain occurred in risk management tasks (+16.6 pp), where enforced dissent led agents to identify overlooked downside scenarios and quantify tail risks more accurately. Quantitative finance tasks achieved the highest overall accuracy (89.7%), demonstrating that structured critique strengthens numerical reasoning in tool-based analyses. Research and investment plan tasks also benefited, with fewer unsupported claims and improved source attribution.
Part IV: Publication
A relevant paper draft has been submitted to AAAI 2026: AI for Finance.
